Task Queues
Task Queues#
The Problem that task queues solve#
You have a web app that needs to do a number of time consuming tasks. However, we know that the best thing to do is respond as quick as possible to the requestor (client). Clients often set a timeout to 5 to 30 seconds. So instead of making the client wait or have the client give a ReadTimeout, rather register those tasks to a task queue and respond to the incoming request as fast as possible.
Task queues are commonly-used in web-based applications, as they allow decoupling time-consuming computation from the request/response cycle.
Another benefit over HTTP is a HTTP server must be listening all the time - if it goes down for a split second the requester will get an error. A task queue however can queue up the requests and respond as soon as the server is available.
Terms#
- Task queue - A system for parallel execution of discrete tasks in a non-blocking fashion (celery, resque)
- Broker - The middleman holding the tasks / messages (rabbitmq, redis)
- Producer - The code that places the tasks to be executed later in the broker (Application code)
- Consumer - Takes tasks from the broker and performs them (A daemon under supervision), also called workers
Message queues are communication buffers between independent sender and receiver processes
Message queues are typically (but not always)
brokers
In Context#
- Sender: Web Servers
- Receiver: Background worker process
When you should consider using a queue#
- Web application takes more than a few seconds to generate a response
- Using a lot of cronjobs
- Do you wish you could distribute processing to many servers
- Processing images and video for the user
- Generating elaborate reports (sent via email)
- Any kind of data synchronisation
- Aggregation of feeds
- A response times out
- Returning an HTTP 202 - Accepted while sending for more processing
Types of Protocols / Brokers#
- AMQP - Advanced Message Queueing Protocol (RabbitMQ, Apache ActiveMQ, OpenAMQ)
- JMS - Java Messaging Service (Apache Qpid, Apache ActiveMQ)
- STOMP - Streaming Text Oriented Messaging Protocol (Apache ActiveMQ, ColiMQ)
Message Queues#
- ZeroMQ - A framework for building message queues
- RabbitMQ - Full package, requiring less configuration. Built in Erlang. Preferred when using ruby or python
- ActiveMQ - Like RabbitMQ, sacrifices raw speed for a richer feature set. Built in Java
Horses for courses#
Ask yourself:
Are you sending messages to communicate between different services in your application or want to process simple background jobs. For simple background jobs the most powerful or flexible message queue is not required.
Message Queues with Django#
Message queues with Python#
Apart from the above
Benefits#
- Multiple separate queues
- Persistence Strategies
- Greater Visibility - you can see volume of messages
- Horizontal scale
- Separate concerns of web application - making it easier to debug, test and maintain
Bad Ideas: Avoiding Task Queues#
- Ignore the long time and make users wait - users are important right?
- Return the page fast with JS and call another script in the browser background - duplicate calls and http cycles are not cool
- cronjob - make a db table and use cron to send the messages - backlogs will destroy you
Example#
@task
def alert_friends(user_id, message):
user = User.objects.get(id=user_id)
for friend in user.friends.all():
friend.send_email(message)
def new_message(request):
user = get_user_od_404(user)
message = request.POST.get('message', None)
if not message:
raise Http404
user.save_new_message(message)
alert_firends.delay(user_id, message)
return redirect(reverse('dashboard'))
Rules#
- Adding a task to the queue should be faster than performing the task itself
- You should consume tasks faster than you produce them, otherwise add more workers
- Ensure your task parameters are serialisable
- Use more queues, not just the default one
- Use celery’s error handling mechanisms
- Use flower for monitoring celery tasks and workers
- Keep track of results only if you really need them
- Don’t serialise a user model, rather use the users id and have the task look it up fresh
- Do not wait for other tasks inside a task
- Prefer idempotent tasks (those that can be applied multiple times and not change the initial result)
- Prefer atomic tasks - it appears to the rest of the system to happen instantaneously
- Set a retry limit to avoid broken tasks continuing forever
- Set a global task timeout
- Exponentially increase retry delays
Use Protobuf as the serialiser if needed
Monitoring and running workers#
A command line that runs a worker is standard.
Use something like supervisord or god to run your workers (consumers)
Build your own task queue#
Nice to play with but don’t reinvent the wheel. Existing task queues:
- Store return results
- Handle Errors
- Route Tasks
- Degrade Gracefully
- Log Activity
Long running requests in an API#
Use asynchronous workers
The default synchronous workers assume that your application is resource-bound in terms of CPU and network bandwidth. Generally this means that your application shouldn’t do anything that takes an undefined amount of time. An example of something that takes an undefined amount of time is a request to the internet. At some point the external network will fail in such a way that clients will pile up on your servers. So, in this sense, any web application which makes outgoing requests to APIs will benefit from an asynchronous worker.
In Practice#
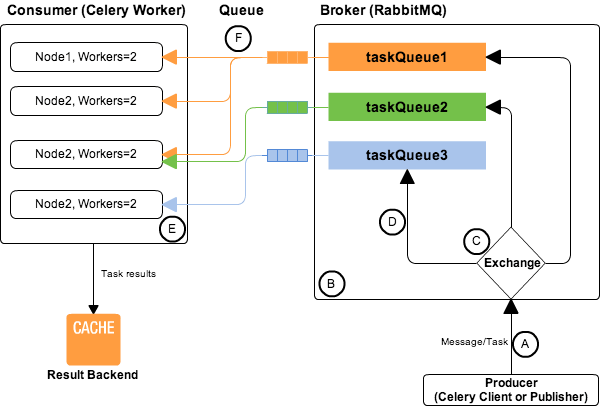
Celery has 3 components:
celery client- interacts with the applicationcelery workers- run long-running tasks asynchronouslymessage broker- keeps track of tasks and queue, so celery workers can consumer them
Optionally celery also provides the option of result back-end to keep track of the status and result of the tasks but in a lot of the cases this feature is not needed.
Check out the docs…start with First steps with Celery. Then you might run into an error:
Received unregistered task of type 'waiting.tasks.waste_time'.
The message has been ignored and discarded.
Did you remember to import the module containing this task?
Or maybe you're using relative imports?
Then move on to use Using celery with django